K8S-08| ETCD 基本介绍

文章目录
【注意】最后更新于 December 22, 2021,文中内容可能已过时,请谨慎使用。
极客时间《云原生训练营》学习笔记。
ETCD 基本介绍
什么是ETCD

etcd 这个名字源于两个想法,即 unix “/etc” 文件夹和分布式系统"d"istibuted。 “/etc” 文件夹为单个系统存储配置数据的地方,而 etcd 存储大规模分布式系统的配置信息。因此,“d"istibuted 的 “/etc” ,是为 “etcd”。
Etcd是CoreOS基于Raft开发的分布式key-value存储,可用于服务发现、共享配置以及一致性 保障(如数据库选主、分布式锁等)。
在分布式系统中,如何管理节点间的状态一直是一个难题,etcd像是专门为集群环境的服务发现 和注册而设计,它提供了数据TTL失效、数据改变监视、多值、目录监听、分布式锁原子操作等 功能,可以方便的跟踪并管理集群节点的状态。
- 键值对存储:将数据存储在分层组织的目录中,如同在标准文件系统中
- 监测变更:监测特定的键或目录以进行更改,并对值的更改做出反应
- 简单: curl可访问的用户的API(HTTP+JSON)
- 安全: 可选的SSL客户端证书认证
- 快速: 单实例每秒1000次写操作,2000+次读操作
- 可靠: 使用Raft算法保证一致性
基础架构
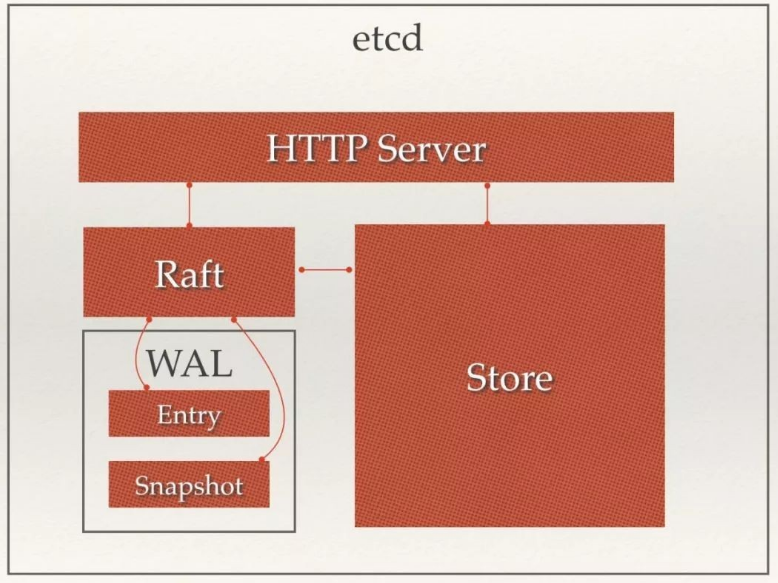
etcd 的简要基础架构图
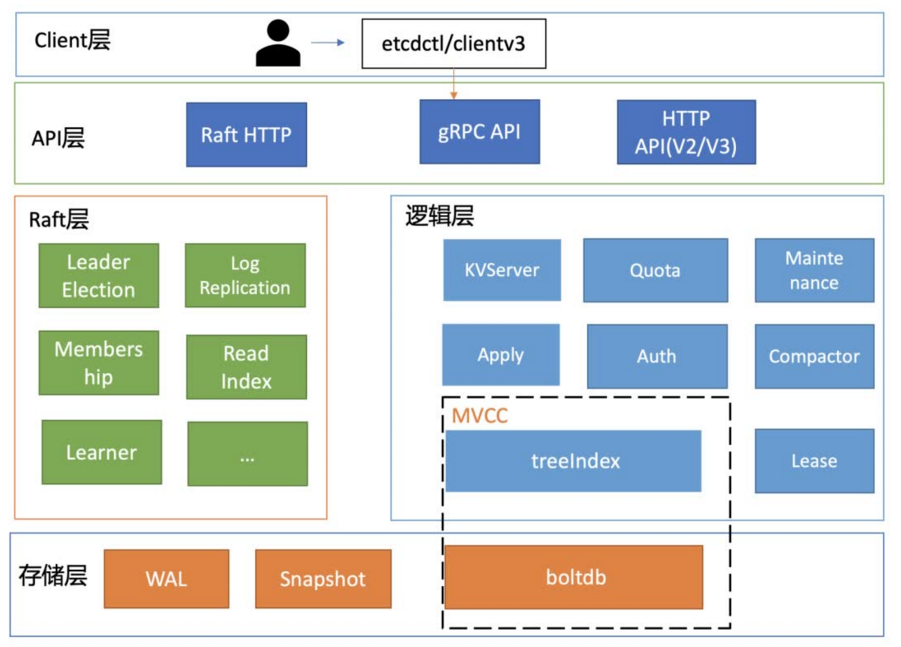
Client 层:Client 层包括 client v2 和 v3 两个大版本 API 客户端库,提供了简洁易用的 API,同时支持负载均衡、节点间故障自动转移,可极大降低业务使用 etcd 复杂度,提升开发效率、服务可用性
API 网络层:API 网络层主要包括 client 访问 server 和 server 节点之间的通信协议。一方面,client 访问 etcd server 的 API 分为 v2 和 v3 两个大版本。v2 API 使用HTTP/1.x 协议,v3 API 使用 gRPC 协议。同时 v3 通过 etcd grpc-gateway 组件也支持 HTTP/1.x 协议,便于各种语言的服务调用。另一方面,server 之间通信协议,是指节点间通过 Raft 算法实现数据复制和 Leader 选举等功能时使用的 HTTP 协议。
Raft 算法层:Raft 算法层实现了 Leader 选举、日志复制、ReadIndex 等核心算法特性,用于保障 etcd 多个节点间的数据一致性、提升服务可用性等,是 etcd 的基石和亮点
功能逻辑层:etcd 核心特性实现层,如典型的 KVServer 模块、MVCC 模块、Auth 鉴权模块、Lease 租约模块、Compactor 压缩模块等,其中 MVCC 模块主要由treeIndex 模块和 boltdb 模块组成。
存储层:存储层包含预写日志 (WAL) 模块、快照 (Snapshot) 模块、boltdb 模块。其中 WAL 可保障 etcd crash 后数据不丢失,boltdb 则保存了集群元数据和用户写入的数据
使用场景
键值对存储
etcd 是一个键值存储的组件,其他的应用都是基于其键值存储的功能展开。
- 采用kv型数据存储,一般情况下比关系型数据库快。
- 支持动态存储(内存)以及静态存储(磁盘)。 • 分布式存储,可集成为多节点集群。
- 存储方式,采用类似目录结构。(B+tree)
- 只有叶子节点才能真正存储数据,相当于文件。
- 叶子节点的父节点一定是目录,目录不能存储数据。
服务注册与发现
- 强一致性、高可用的服务存储目录。
- 基于 Raft 算法的 etcd 天生就是这样一个强一致性、高可用的服务存储目录。
- 一种注册服务和服务健康状况的机制。
- 用户可以在 etcd 中注册服务,并且对注册的服务配置 key TTL,定时保持服务的心跳以达 到监控健康状态的效果。
消息发布与订阅
- 在分布式系统中,最适用的一种组件间通信方式就是消息发布与订阅。
- 即构建一个配置共享中心,数据提供者在这个配置中心发布消息,而消息使用者则订阅他们关心的主题,一旦主题有消息发布,就会实时通知订阅者。
- 通过这种方式可以做到分布式系统配置的集中式管理与动态更新。
- 应用中用到的一些配置信息放到etcd上进行集中管理。
- 应用在启动的时候主动从etcd获取一次配置信息,同时,在etcd节点上注册一个Watcher并等待,以后每次配置有更新的时候,etcd都会实时通知订阅者,以此达到获取最新配置信息的目的。
节点最佳实践

集群中节点总数 (Instances) 对应的 Quorum 数量,用 Instances 减去 Quorom 就是集群中容错节点(允许出故障的节点)的数量。
所以在集群中推荐的最少节点数量是 3 个,因为 1 和 2 个节点的容错节点数都是 0,一旦有一个节点宕掉整个集群就不能正常工作了。
当决定集群中节点的数量时,强烈推荐奇数数量的节点, 比如下图表中高亮的那几个选项。

具体来说,6 个节点的集群它的容错能力并没有比 5 个节点的好,他们的容错节点数一样,一旦容错节点超过 2 后,由于 Quorum 节点数小于 4 整个集群也变为不可用的状态了。
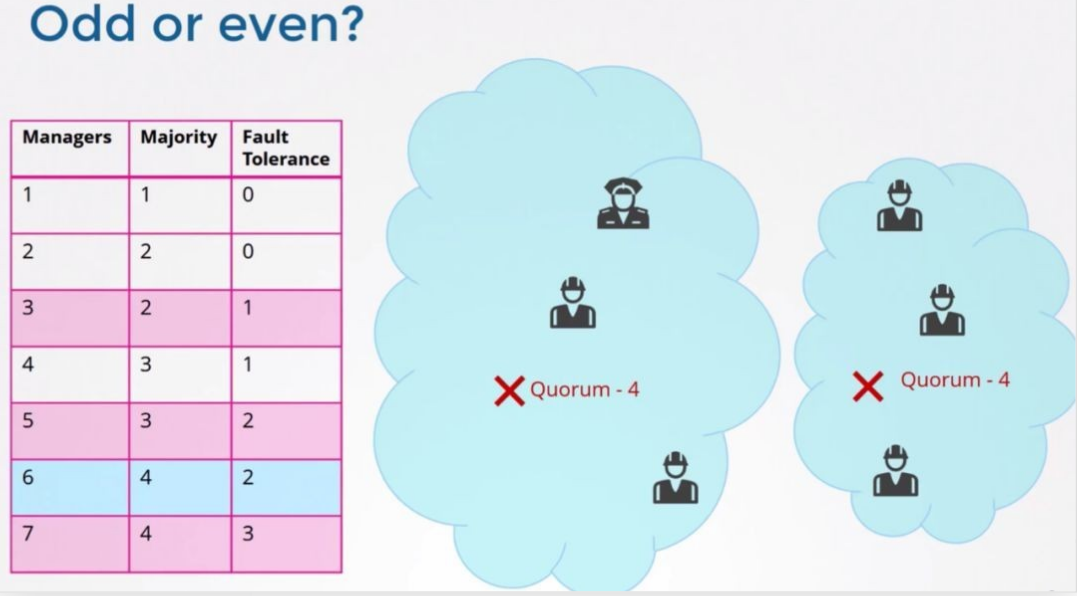
所以在决定集群中的节点数时,奇数要优于偶数
使用案例
- CoreOS 的容器 Linux: 在Container Linux上运行的应用程序获得自动的不宕机 Linux 内核更新。 容器 Linux 使用locksmith来协调更新。locksmith 在 etcd 上实现分布式信号量,确保在任何给定时间只有集群的一个子集重新启动。
- Kubernetes 将配置数据存储到etcd中,用于服务发现和集群管理; etcd 的一致性对于正确安排和运行服务至关重要。Kubernetes API 服务器将群集状态持久化在 etcd 中。它使用etcd的 watch API监视集群,并发布关键的配置更改。