K8S-02| Google Borg

文章目录
【注意】最后更新于 December 7, 2021,文中内容可能已过时,请谨慎使用。
极客时间《云原生训练营》学习笔记。
K8S-02| Google Borg
Borg 简介
特性
物理资源利用率高。
为什么资源利用率高?大家想一想它没有虚拟化,没有虚拟化就意味着类似于我们容器技术和虚拟机的比较,我的所有计算资源全部用来给作业了,额外开销的部分少了,它还有混合部署,混部有什么特征呢?需求都有波峰波谷,我们醒着的时候都会去访问网站,一个明显的特征就是每天白天访问量上去,资源利用率就上去了,晚上大家都睡觉了,它的资源利用率就下来了。那么在晚上所有的这种物理资源是不是就浪费掉了,混部在晚上的时候跑一些短时作业,离线作业,通过这种方式,它可以提高资源利用率。
服务器共享,在进程级别做隔离。
Namespace 做隔离
应用高可用,故障恢复时间短。
调度策略灵活。
应用接入和使用方便,提供了完备的 Job 描述语言,服务发现,实时状态监控和诊断工具。
一个完善的Job语言描述。
一切的请求,一切的业务需求,你都定义一个对象,这个对象发给控制平面,然后由控制平面去执行
优势
- 对外隐藏底层资源管理和调度、故障处理等。
- 实现应用的高可靠和高可用。
- 足够弹性,支持应用跑在成千上万的机器上。
基本概念
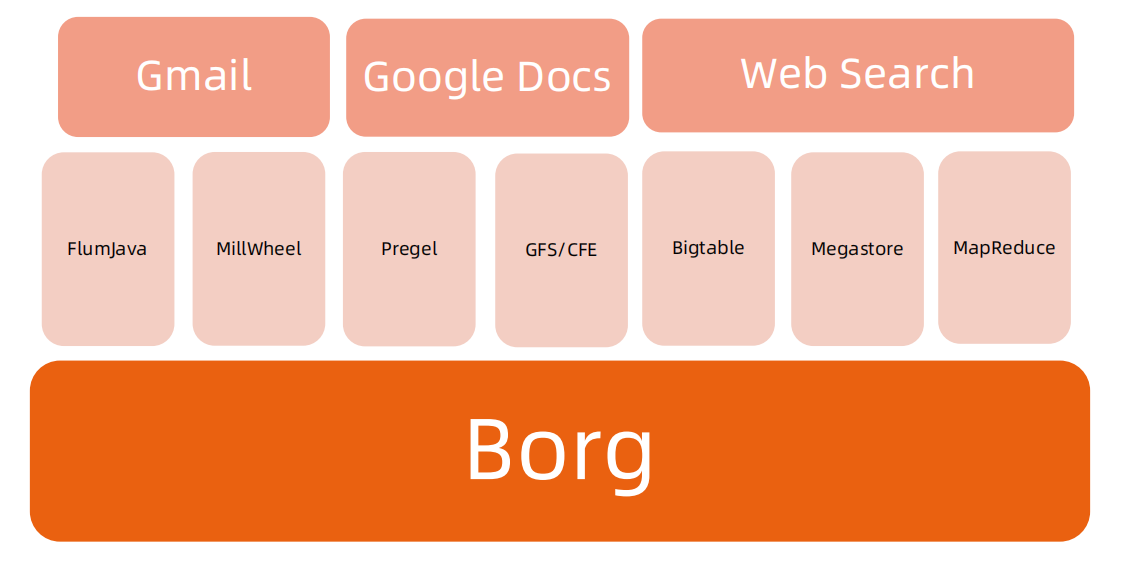
Workload prod:在线任务,长期运行、对延时敏感、面向终端用户等,比如Gmail, Google Docs,Web Search 服务等。 non-prod :离线任务,也称为批处理任务(Batch),比如一些分布式计算服务等。一跑完就结束的
Cell 一个 Cell 上跑一个集群管理系统 Borg。 通过定义 Cell 可以让Borg 对服务器资源进行统一抽象,作为用户就无需知道自己的应用跑在哪台机器上,也不用关心资源分配、程序安装、依赖管理、健康检查及故障恢复等。
Job 和 Task 用户以 Job 的形式提交应用部署请求。一个Job 包含一个或多个相同的 Task,每个 Task运行相同的应用程序,Task 数量就是应用的副本数。 每个 Job 可以定义属性、元信息和优先级,优先级涉及到抢占式调度过程。
Naming
提供服务注册和服务发现
Borg 的服务发现通过BNS ( Borg NameService)来实现。 50.jfoo.ubar.cc.borg.google.com 可表示在一个名为 cc 的 Cell中由用户 uBar 部署的一个名为 jFoo 的 Job下的第50个 Task。
Borg架构
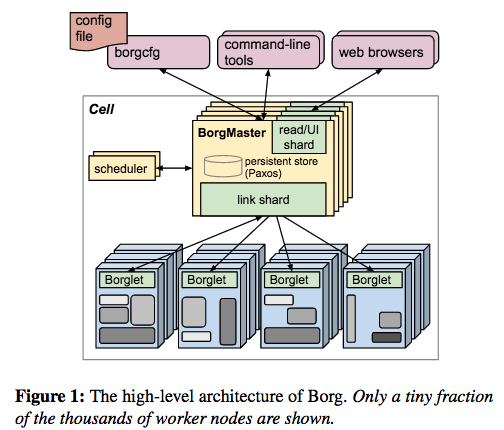
- UI 接受请求
- Paxos 存数据保证数据一致性
- scheduler 调用任务 下发请求
- Borglet 接收任务并上报状态
Borgmaster 主进程:
处理客户端 RPC 请求,比如创建 Job,查询 Job 等。
维护系统组件和服务的状态,比如服务器、Task 等。
负责与 Borglet 通信。
Scheduler 进程:
- 调度策略
- Worst Fit(最差适应算法), 找最空闲的机器
- Best Fit (最佳适应算法),尽量把一个节点装满,再去装下一个, 可以节省成本
- Hybrid
- 调度优化
- Score caching: 当服务器或者任务的状态未发生变更或者变更很少时,直接采用缓存数据,避免重复计算。
- Equivalence classes: 调度同一 Job 下多个相同的 Task 只需计算一次。
- Relaxed randomization: 引入一些随机性,即每次随机选择一些机器,只要符合需求的服务器数量达到一定值时,就可以停止计算,无需每次对 Cell 中所有服务器进行 feasibility checking。
- Borglet:
- Borglet 是部署在所有服务器上的 Agent,负责接收 Borgmaster 进程的指令。
应用高可用
- 被抢占的 non-prod 任务放回 pending queue,等待重新调度。
- 多副本应用跨故障域部署。所谓故障域有大有小,比如相同机器、相同机架或相同电源插座等,一挂全挂。
- 对于类似服务器或操作系统升级的维护操作,避免大量服务器同时进行。
- 支持幂等性,支持客户端重复操作。
- 当服务器状态变为不可用时,要控制重新调度任务的速率。因为 Borg 无法区分是节点故障还是出现了短暂的 网络分区,如果是后者,静静地等待网络恢复更利于保障服务可用性。
- 当某种“任务 @ 服务器”的组合出现故障时,下次重新调度时需避免这种组合再次出现,因为极大可能会再 次出现相同故障。
- 记录详细的内部信息,便于故障排查和分析。
- 保障应用高可用的关键性设计原则:无论何种原因,即使 Borgmaster 或者 Borglet 挂掉、失联,都不能杀 掉正在运行的服务(Task)
Borg 系统自身高可用
- Borgmaster 组件多副本设计。
- 采用一些简单的和底层(low-level)的工具来部署 Borg 系统实例,避免引入过多的外部依赖。
- 每个 Cell 的 Borg 均独立部署,避免不同 Borg 系统相互影响。
资源利用率
- 通过将在线任务(prod)和离线任务(non-prod,Batch)混合部署,空闲时,离线任务可以充分利用计 算资源;繁忙时,在线任务通过抢占的方式保证优先得到执行,合理地利用资源。
- 98% 的服务器实现了混部。
- 90% 的服务器中跑了超过 25 个 Task 和 4500 个线程。
- 在一个中等规模的 Cell 里,在线任务和离线任务独立部署比混合部署所需的服务器数量多出约20%-30%。 可以简单算一笔账,Google 的服务器数量在千万级别,按 20% 算也是百万级别,大概能省下的服务器采 购费用就是百亿级别了,这还不包括省下的机房等基础设施和电费等费用。
Brog 调度原理
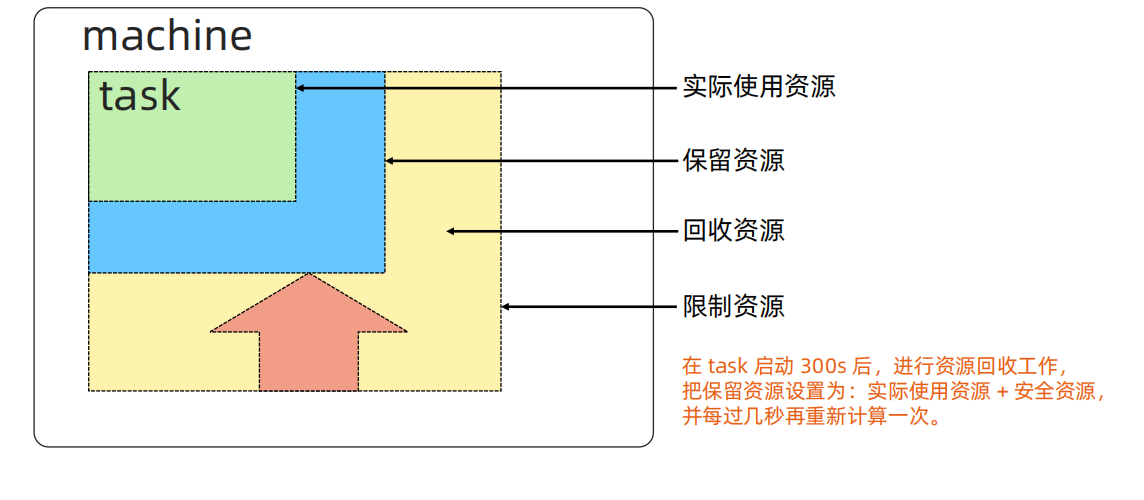
这里面暴露了一些它的一些实现细节就是怎么样提高资源的利用率?
它在当你用户跑一个作业的时候,你需要去设置你的资源。但很多时候其实用户他不知道资源,自己的资源的利用是多少,比如说你开发了一个应用,就拿上次的作业,你应该跑多少,你知道吗?其实很难很难去评估的,那这里面你可能要涉及到一般来说是怎么样的?比如说 资源利用率是怎么算出来呢?第一,去看线上的每天的访问量然后把它平均细分到某一个高峰时段,所能接收到的QPS是多少,比如说50,那么我就要以这个QPS乘以一个buffer比如说60或者70,这样的一个QPS去压应用,然后压的时候去观测他的cup和mem占多少,然后我再以这个为数值作为参考,去按我的这个资源利用情况去申请资源。那brog本身会做一些动态的动态的计算,他怎么做呢?就是说我让你设你可以设得很高,但是接下来我会去监控你的资源利用率,在启动的 300s 以后它会一直做评估,评估你的真实使用率,比如说只有绿色的框框这么点,如果你申请了黄色框这么多,那么意味着中间的这一部分其实都是可以回收的。那么它会保守的相当于你现在用了这么多,给你留一段空间,这个时候其他资源就回收了,这个资源又可以被别的作业做了。
公有云上这个都是做好的, 自建的云需要自已处理
隔离性
安全性隔离:
- 早期采用 Chroot jail,后期版本基于 Namespace。
性能隔离:
采用基于 Cgroup 的容器技术实现。
在线任务(prod)是延时敏感(latency-sensitive)型的,优先级高,而离线任务(non-prod, Batch)优先级低。
Borg 通过不同优先级之间的抢占式调度来优先保障在线任务的性能,牺牲离线任务。
Borg 将资源类型分成两类:
- 可压榨的(compressible),CPU 是可压榨资源,资源耗尽不会终止进程;
- 不可压榨的(non-compressible),内存是不可压榨资源,资源耗尽进程会被终止。
从用户的角度来说,虽然是同时执行的,那么为什么是可压榨的呢?假设说CPU我本来应该分80毫秒但是我只分了40,其他被别人占用去了。那这样的话,你从应用程序的角度来说,只能感觉是慢,那慢一点没关系,慢一点又不会有太大的问题,你可能是用户多了一毫秒,多了两毫秒,它可能感受也不是很深,所以这种是可压榨资源,所以对可压榨资源,我们就对它没有那么好,就不需要关照的特别厉害,所以偶尔超一下没关系的,但是对于内存来说就不一样了,内存一旦超限大部分情况下就会OOM,所以我们对内存要格外关照,所以这种资源是不可压缩资源。